ISSN : 0975-2927
EISSN : 0975-9166

CHAVAN S.V.1*, KALE K.V.2, KAZI M.M.3, RODE Y.S.4
1Department of CSIT, MSS’s ACS College, Ambad, Jalna- 431 213, MS, India.
2Department of CSIT, Dr. Babasaheb Ambedkar Marathwada University, Aurangabad- 431 004, MS, India.
3Department of CSIT, Dr. Babasaheb Ambedkar Marathwada University, Aurangabad- 431 004, MS, India.
4Department of CSIT, Dr. Babasaheb Ambedkar Marathwada University, Aurangabad- 431 004, MS, India.
* Corresponding Author : shripc@gmail.com
Received : 30-03-2013 Accepted : 15-04-2012 Published : 20-04-2013
Volume : 5 Issue : 1 Pages : 421 - 425
Int J Mach Intell 5.1 (2013):421-425
DOI : http://dx.doi.org/10.9735/0975-2927.5.1.421-425
Conflict of Interest : None declared
The recognition of Handwritten Devanagari character plays a vital role in the research area. Number of approaches has been used in preceding researches and still it is being carried out ahead. In this research paper, Geometric and Zernike moment features of Devanagari basic and compound Character are used to recognize the handwritten character. Compound character is a special feature of Devanagari scripting; it joins two or more character in various ways forming a new character. The complexity and frequency occur in writing the compound character is more as compared to other languages. The proposed system is trained and tested on 27000 handwritten Devanagari basic and compound character database collected from different people. Each image is normalized to 30X30 pixel size. For recognition of Devanagari basic and compound character we have used MLP and KNN. The recognition rate is 98.78% and 95.56% which is comprehensive to the method.
Handwritten Devanagari compound character, Geometric moment, Zernike Moment, MLP KNN.
Handwritten character recognition is the important area in image processing and pattern recognition fields. This field of research is applicable to various application areas where the aim is too atomized and reduces the human efforts for form filling, job application, bank and postal automation [1-3] etc. Handwritten character recognition in Indian script [4] is a challenging task specially Devanagari, for several reason like complex structure of character with their modifiers and present of compound character. Compound character are those where two or more character are joined together to produce a special character. These characters are such type in which one half of character is connected to full character. Thus there are large variations in shape of character as writing style, pen quality (thick/thin), strokes that substantial extent the recognition accuracy. Writing style in Devanagari script is from left to right. The concept of upper/lower case is absent in Devanagari script. In Devanagari script a vowel following a consonant takes a modified shape. Depending on the vowel, its modified shape is placed at the left, right (or both) or bottom of the consonant. These modified shapes are called modified characters. A consonant or vowel following a consonant sometimes takes a compound orthographic shape, which we call as compound character.
Work on Devanagari was started early in 1970. Sinha and Mahabala [5] presented a syntactic pattern analysis system for the recognition of handwritten and machine printed Devnagari characters. OCR work for printed and handwritten characters in various Indian scripts [6-8] is carried out by researchers but major work is found for Bangla [9,10] and Devanagari. First research report on handwritten Devanagari character was published in 1977 by Sethi and Chatterjee [11] . They proposed an MLP neural network-based classification approach for the recognition and obtained 91.28% results. An extensive research work on printed Devanagari was carried out by Bansal and Sinha [12-14] . First, Handwritten numerals of Devanagari work was presented by Bajaj, Dey and Chaudhury [15] proposed a multi-classifier connectionist architecture for recognition and they obtained 89.6% accuracy. Patil and Sontakke [16] presented an algorithm for handwritten Devanagari numerals recognition which was rotation, scale and translation invariant using Fuzzy Neural Network. Hanmandlu and Murty [17] who proposed Fuzzy model-based recognition of Handwritten Hindi Numerals and they obtained 92.67% accuracy. Kumar and Singh [18] proposed a Zernike moment-based technique and obtained 80% recognition rate. Sharma and Pal [19] made an important contribution using Chain Code Histogram with an accuracy of 80.36%. Hanmandlu and Murty published a Fuzzy-based system [20] and achieved 90.65% accuracy. Pal, Sharma, T. Wakabayashi and Kimura [21] proposed a method based on directional information obtained from the arc tangent of the gradient yielding 94.24% recognition rate. Another significant contribution is due to Arora and Bhattacharjee in which they proposed a multi-feature extraction based technique thereby achieving 92.8% accuracy [22] . Pal and T. Wakabayashi proposed SVM and MQDF based scheme and achieved recognition accuracy as high as 95.13% [23] . U. Pal and T. Wakabayashi [24] proposed a comparative study of different Devanagari character recognizers using features based on curvature and gradient information obtained from binary as well as gray-scale document images. S. Shelke and S. Apte [25] in their paper presented a novel approach for recognition of unconstrained handwritten Marathi characters. The recognition rate achieved from the proposed method is 95.40%. Baheti M.J. and Kale [26] proposed a method based on affine invariant moments for Gujarati numerals the recognition rate was 90% for KNN and 84% for PCA. Recognition of handwritten Bangla compound character was attempted by U. Pal and T. Wakabayashi [27] using gradient features. Recently, some pieces of work are found on handwritten Marathi compound characters [28] by S. Shelke and S. Apte. While significant advances have been achieved in recognizing Roman-based scripts like English, ideographic characters (Chinese, Japanese, Korean, etc.) and Arabic to some extent, OCR research on Indian scripts is very thin. Only few works on some of the major Indian scripts like Devnagari, Bangla, Gurumukhi, Tamil, Telugu, etc. are available in the literature.
The paper is organized as follows: Section 2 deals with Devanagari language, its character set, and Section 3 Database collection for the experiment. Preprocessing & Feature extraction procedure is presented in Section 4. Section 5 details the classifier used for recognition. The experimental results are discussed in Section 6. Finally, conclusion on the paper is given in Section 7.
The basic set of symbols of Devanagari script consists of 12 vowels (or swar), 36 consonants (or vyanjan) as shown in [Fig-1] , we have also used 45 compound character + 15 split component of compound character for proposed research which is presented in [Fig-2] .
Compound characters can be combinations of two consonants as well as a consonant and a vowel. Compounding of three or four characters also exists in the script. The compound characters are joined in various ways, by removing vertical line of the character and then join it to the other character from left side like मà¥à¤¯, or another way is join side by side or one above the other The e.g. regarding to the compound is shown in [Fig-3] . Split character is the half character of basic character which get connected to other character e.g. regarding split is given in [Fig-4] .
To attain the recognition accuracy of join strategies of compound character the structural classification is required. There are two routes for recognition of compound character. One way by separation of the character and second is without separation. For first method two separate features are extracted and then recognition is done. For second method without separation the feature are extracted. At present no dataset on Devanagari handwritten compound characters is available. The data collection procedure is explained in the following section.
In the proposed system, we are going to recognized Devanagari Basic as well as Compound character by extracting the structural and statistical features extraction. We have considered 48 basic characters i.e. vowels & consonant as shown in [Fig-1] and 60 compound characters as shown in [Fig-2] . In Devanagari, characters are written from left to right. Every character has horizontal bar called ‘shrirorekha’ at the top and some of them have vertical bar either on right or middle or absence of it. These characters are pre-classified separately on the basis of global and local features in turn from it Geometric and Zernike moment features are extracted. Before testing the system prior the MLP is trained done with this feature.
A significant contribution of present work is the pioneering development of large database for Handwritten Devanagari Basic and Compound Character was collected. Several details of this database are provided.
The Handwritten Devanagari (Basic & Compound) character databases consist of 27000 samples written by writer from different location, fields, profession etc. The database is divided into respective training and testing set approximately into the ratio of 4:1. The details of this database are given in [Table-1] .
Preprocessing is an important step of applying a number of procedures for smoothing, enhancing, filtering etc., for making a digital image usable by subsequent algorithm in order to improve their readability. The preprocessing plays important role in handwritten character recognition as in pattern recognition task. There are various stages includes binarization, opening and closing operations.
In pattern recognition, feature extraction stage in character recognition plays a major role in improving the recognition accuracy [29] . Here the features are extracted from binary image/characters. The characteristics used for classification lay in the shape variations. Many characters are misclassified due to their similarity in shape or slight variation in writing style. So features which are selected should tackle these problems.
In structural classification, there is wide range of variations in the writing the character (basic or compound) so pre-classification of the character is needed. This classification is based on two stages i.e. global features and local features. The global features like presence of vertical line, position of it in the character and enclosed region in the character. The local features like end points and position in the character.
On the basis of global feature, the character is classified into three major categories based on the presence of vertical bar i.e. the end-bar character, the middle-bar character, and the character without any bar. To detect the presence of vertical bar in the character, divide the character into 3x3 examine column 1x3, 2x3, 3x3 for end-bar and 1x2, 2x2, 3x2 for middle bar. The average number of pixel in the column contain for than 80% of the column with black pixel. The rest of the characters are without a bar.
End bar are further classified into two categories based on whether the vertical bar and rest of the character are connected or not to the bar. These are show in the [Table-2] .
The local features are detected on the bases of the end points of the character. To detect the end points there are two steps, first partitioned the image into 3x3 i.e. 9 quadrants and secondly detect the end points in the individual block as shown in [Fig-5] .
In the proposed work basic, compound character are written on plain paper. The characters are scanned, pre-processed by the above discussion and store automatically for database creation. The character is processed, normalized into the required size and transfer for structural classification and further features are extracted which are used for training and testing.
The cropped images for structural classification are resized into fixed size to extract the features. On the basis of pre-classification moment Geometric and Zernike moment features are extracted. The feature extraction procedures are explained below.
Moment based features are extracted form the each zone of the scaled character bitmapped image. The image is partitioned into zone as shown in [Fig-6] and features are extracted from each zone. In this paper Geometric and Zernike moments based feature extraction is proposed for off-line Devnagari Handwritten Character. To get the feature, at first, the image is segmented to 30 x 30 blocks, and partitioned as feature set as follows.
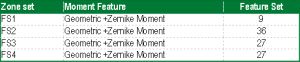
Feature set a- Figure shows 1 is considered as whole.
Feature set b- Figure shows 2 dividing the image into four equal zones.
Feature set c- Figure shows 3 dividing the image into three vertical equal zones.
Feature set d- Figure shows 3 dividing the image into three horizontal equal zones.
The concept of moment in mathematics evolved from the concept of moment in physics. It is an integrated theory system. For both contour and region of a shape, one can use moment's theory to analyze the object.
Geometric moments are computed using conventional method and this involved translation, scale and rotation invariants, Zernike moments are computed in corresponding with geometric moments’ expression to achieve translation and scale invariants.
The geometric moments are basically projections of the image function onto the monomials, i.e., Ï•nm (x, y) = xnym, the (n+m)th order geometric moment, Mnm, is defined in [Eq-1]
The geometric moments are most widely used in image analysis and pattern recognition tasks. This is due essentially to their simplicity, the invariance and geometric meaning of the low order moment values. In fact, the zeroth order moment, M00, represents the total mass of the image. The two first order moments, (M10, M01), provide the position of the center of mass. The second order moments, (M20, M11, M02), can be used to determine several useful image features such as the principal axes, the image ellipse and the radii of gyration [31] .
The Zernike moments use the complex Zernike polynomials as the moment basis set. The 2D Zernike moments, Znm, of order n with repetition m, are defined in polar coordinates (r, θ) inside the unit circle as [28]
0 £ |m| £ n, n - |m| is even
where Rnm(r) is the nth order of Zernike radial polynomial given by
(3)
Like the rotational moments and the complex moments, the magnitude of the Zernike moments is invariant under image rotation transformation. The image can be reconstructed using a set of moments through order M as
The classification stage is the decision making part of a recognition system and it uses the features extracted in the previous stage. We have used Multilayer Perceptron (MLP) and K-NN for the purpose of Classification and recognition.
We selected Multi Layer Perceptron (MLP) as the classifier. This class of networks consists of 3 layers including one hidden layer for four different feature set consist of FS1 to FS4. The experimental result that we obtained with the help of these features for recognition of handwritten Devanagari basic and compound character is described in next section. The classifier is trained with Standard Backpropagation. It minimizes the sum of squared error for training sample by conducting a gradient descent search in the weight space. Activation function as sigmoid function, Learning Rate and Momentum as 0.8 and 0.7 respectively. Number of neurons in input layer is 9, 36, 27, 27 for Feature Set FS1 to FS4. Number of Hidden layer is flexible we have done experiment on 20 to 90 to get optimal result and finally it was set to 20,30,40,50 and 60 for all feature set. The output layer contain one node for each class, therefore the no of neuron at output for each character is 108.
The k-NN classification is that similar observations belong to similar classes. The test numeral feature vector is classified to a class, to which its nearest neighbor belongs to. The nearest factor is based on minimum Euclidean Distance. Feature vectors stored priori are used to decide the k-nearest neighbor of the given feature vector.
In the field of character recognition, it is now recognized that a one single feature and a single classification algorithm generally cannot yields a very low error rate. Therefore it is proposed that the combination features can create better success rates. Geometric and Zernike Moment feature are extracted from the discussed feature set. The details of feature set are in [Table-3] .
Each image is partitioned into feature set FS1, FS2, FS3, FS4 and from each zone of it Geometric and Zernike Moment feature are extracted. These feature set for each character extracted individually and specified in [Table-3] .
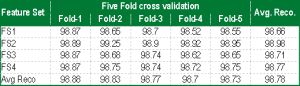
The original training and testing set of Devanagari basic character are discussed in section 3.1, the database consist of 12000 basic Devanagari character from which we have selected 9600 for training and 2400 for testing. The database also consist of 11250 compound and 3750 split Devanagari Character we have apply the k-fold crossing validation technique. First structural pre-classification is done as discuss in section 4 and then moment based features are extracted from feature set as discuss in section 5. The performance using MLP is presented in [Table-4] . The results are encouraging and average recognition accuracy is 98.78% is obtained. Recognition accuracy using k-NN classifier is presented in table 5. Overall recognition rate is 95.56%.
The accuracy of individual Devanagari Characters was also computed. Maximum accuracy of 96.23% was achieved for the Devanagari Character à¤, and ग this is because of its unique shape. In this next higher accuracy of about 97.56% was achieved for the character त and च In this we also notice the confusing pair of Devanagari Character and their error rates for घ and ध were 0.65% and for थ and य were 0.59%. From this we noticed that similar shapes of characters are of confused to the system.
In this paper we have proposed handwritten Devanagari Compound character recognition system which consists of moment based features and using simple feed forward Multilayer Perceptrons. Not much of the work is done on the compound character we have obtain better result from the moment based feature. Further we are applying orthogonal moment on the compound character to get better result.
[1] Roy K., Vaidya S., Pal U., Chaudhuri B.B. and Belaid A. (2005) Proc. 8th Int. Conf. Document Analysis and Recognition, Seoul, Korea, 31(8), 1060-1064.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[2] Pal U., Roy R.K., Roy K. and Kimura F. (2009) Proc. 10th Int. Conf. Document Analysis and Recognition, Barcelona, Spain, 26(6), 456-460.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[3] Chaudhari B.B. (2007) Digital Document Processing-Major Directions and Recent Advances, London: Springer.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[4] Pal U. and Chaudhari B.B.(2004) Pattern Recognition, 1887-1899.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[5] Sinha R.K., and Mahabala (1979) IEEE Trans. System Man Cyber, 435-441.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[6] Chaudhuri B.B. and Pal U. (1998) Pattern Recognition, 531-549.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[7] Roy K., Pal T., Pal U. and Kimura F. (2005) Proc. 8th Int. Conf. Document Analysis and Recognition, Seoul, Korea, 31(8),770-774.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[8] Pujari A., Naidu D.C., Sreenivasa Rao M. and Jinaga B.C. (2004) Image and Vision Computing, 1221-1227.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[9] Bhattacharya U., Ghosh S.K. and Parui S.K. (2007) Proc. 9th Int. Conf. Document Analysis and Recognition Parana, 23(9), 511-515.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[10] Chaudhuri B.B. and Pal U. (1998) Pattern Recognition, 531-549.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[11] Sethi I.K. and Chatterjee B. (1977) Pattern Recognition, 69-75.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[12] Bansal V. (1999) Integrating Knowledge Sources in Devanagari Text Recognition, Ph.D. Thesis, IIT Kharagpur.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[13] Bansal V. and Sinha R.M.K. (1999) Proc. 5th Int. Conf. Document Analysis and Recognition, Bangalore, India, 20(9), 53-65.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[14] Bansal V. and Sinha R. M. K. (1999) Proc. 5th Int. Conf. Document Analysis and Recognition, Bangalore, India, 20(9), 410-413.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[15] Bajaj R., Dey L. and Chaudhury S. (2002) Sadhana, 59-72.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[16] Patil P.M. and Sontakke T.R. (2007) Pattern Recognition, 2110-2117.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[17] Hanmandlu M. and Murthy Ramana O.V. (2005) Int. Conf. on Cognition and Recognition, 490-496.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[18] Kumar S. and Singh C. (2005) Proc. Intl. Conf. Cognition & Recognition, Mandya (India), 514-520.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[19] Sharma N., Pal U., Kimura F. and Pal S. (2006) Proc. Indian Conf. Computer Vision Graphics & Image Processing, Madurai (India), 805-816.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[20] Hanmandlu M., Murthy Ramana O.V. and Madasu V.K. (2007) Proc. Ninth Biennial Conf. Australian Pattern Recognition Society on Digital Image Computing Techniques and Applications, Glenelg (Australia), 454-461.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[21] Pal U., Sharma N., Wakabayashi T. and Kimura F. (2007) Proc. Ninth Intl. Conf. Document Analysis & Recognition, Curitiba (Brazil), 496-500.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[22] Arora S., Bhattacharjee D., Nasipuri M., Basu D.K., and Kundu M. (2008) Proc. IEEE Region 10 Colloquium and Third Intl. Conf. Industrial & Information Systems, Kharagpur (India).
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[23] Pal U., Chanda S., Wakabayashi T. and Kimura F. (2008) Proc. Eleventh Intl. Conf. Frontiers in Handwriting Recognition, Montreal (Canada), 367-372.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[24] Pal U., Wakabayashi T. and Kimura F. (2009) Proc. Tenth Intl. Conf. Document Analysis & Recognition, Barcelona (Spain), 1111-1115.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[25] Shelke S. and Apte S. (2010) 12th International Conference on Frontiers in Handwriting Recognition.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[26] Baheti M.J., Kale K.V. and Jadhav M.E. (2011) International Journal of Machine Intelligence (IJMI), 160-163.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[27] Pal U., Wakabayashi T. and Kimura F. (2007) Proc. 10th Int. Conf. Information Technology, Orissa, India, 17(12), 208-213.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[28] Shelke S. and Apte S. (2011) International Journal of Signal Processing, Image Processing and Pattern Recognition, 81-94.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[29] Saharia S., Bora P.K. and Saikia D.K. (2004) Proc. 4th ICVGIP, 491-496.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[30] Kumar S. and Singh C. (2005) Proc. Intl. Conf. on Cognition and Recognition, 514.520.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[31] Prokop R.J. and Reeves A.P. (1992) CVGIP: Graphical Models and Image Process, 438-460.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[32] Teague M.R. (1980) J. Opt. Soc. Am., 920-93.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
 | Fig. 1- Vowels and Consonants of Devnagari Script |
 | Fig. 2- Compound and Split Character |
 | Fig. 3- Example of Compound Character |
 | Fig. 4- Example of Split of Compound Character |
 | Fig. 5- Presence of End Points of character in block |
 | Fig. 6- Partition of Devanagari Character for Feature Set. |
 | Table 1- Devanagari Character Dataset use for training and testing |
 | Table 2- Classification of Devanagari Character |
 | Table 3- Moment Feature set for Devanagari Character |
 | Table 4- Recognition Result in % using MLP classifier |
 | Table 5- Recognition Result in % using K-NN classifier |